Published on Monday, 2021-05-31 at 12:00 UTC
Failing Big with Elixir and LiveView
A post-mortem of why a political party in Germany had to delay their convention by an hour.

Phoenix LiveView is, without a doubt, one of the greatest web development innovations in recent years. In this article, I will explore how I created one of the world’s first production deployments with LiveView - and how I caused a lot of trouble while trying to improve it.
If you’re already familiar with LiveView, feel free to skip to the following two paragraphs. For everyone else, here’s here’s a quick explanation of what LiveView is:
LiveView is part of Elixir’s Phoenix web framework and lets you build interactive applications without needing to write your own front-end JavaScript. It does that by keeping the application state on the server. When the application state changes, it automatically pushes an update to the user’s browser via Websockets. At the same time, it can also send user events (such as button clicks or form submits) back to the server. And all that, automagically, without the need to worry about front-end JavaScript.
For me, LiveView has meant unparalleled speed when developing web applications. What’s more, I find that writing all code in Elixir really reduces the mental load that usually comes from juggling a backend language with JavaScript for the frontend. And so it’s no surprise that the Ruby and PHP communities have come up with their own spins of the idea, StimulusReflex and Livewire.
It All Started In Prague - And Bulgaria
Back in summer 2019, LiveView was still in its early stages. Chris McCord had announced it only a few months earlier and the first version had just been released in August. After having seen Chris’s keynote on LiveView at ElixirConf EU in Prague, Czechia, I was excited to give it a shot.
The event ended up being a great success for what was likely one of the
first LiveView production deployments in the world.
Fortunately, an opportunity to put this new technology to work had just presented itself: Volt Europa, a transnational and pan-European progressive party, had just been officially incorporated and they were looking to organize their first big General Assembly. With its members spread out across the European continent, being online had been part of Volt’s DNA from the start. This is why it was quickly agreed that its first convention would be held as hybrid event. A number of members would gather in Sofia, Bulgaria - but an even larger number would follow the event from home, participating digitally.
The Architecture of an Online Party Convention
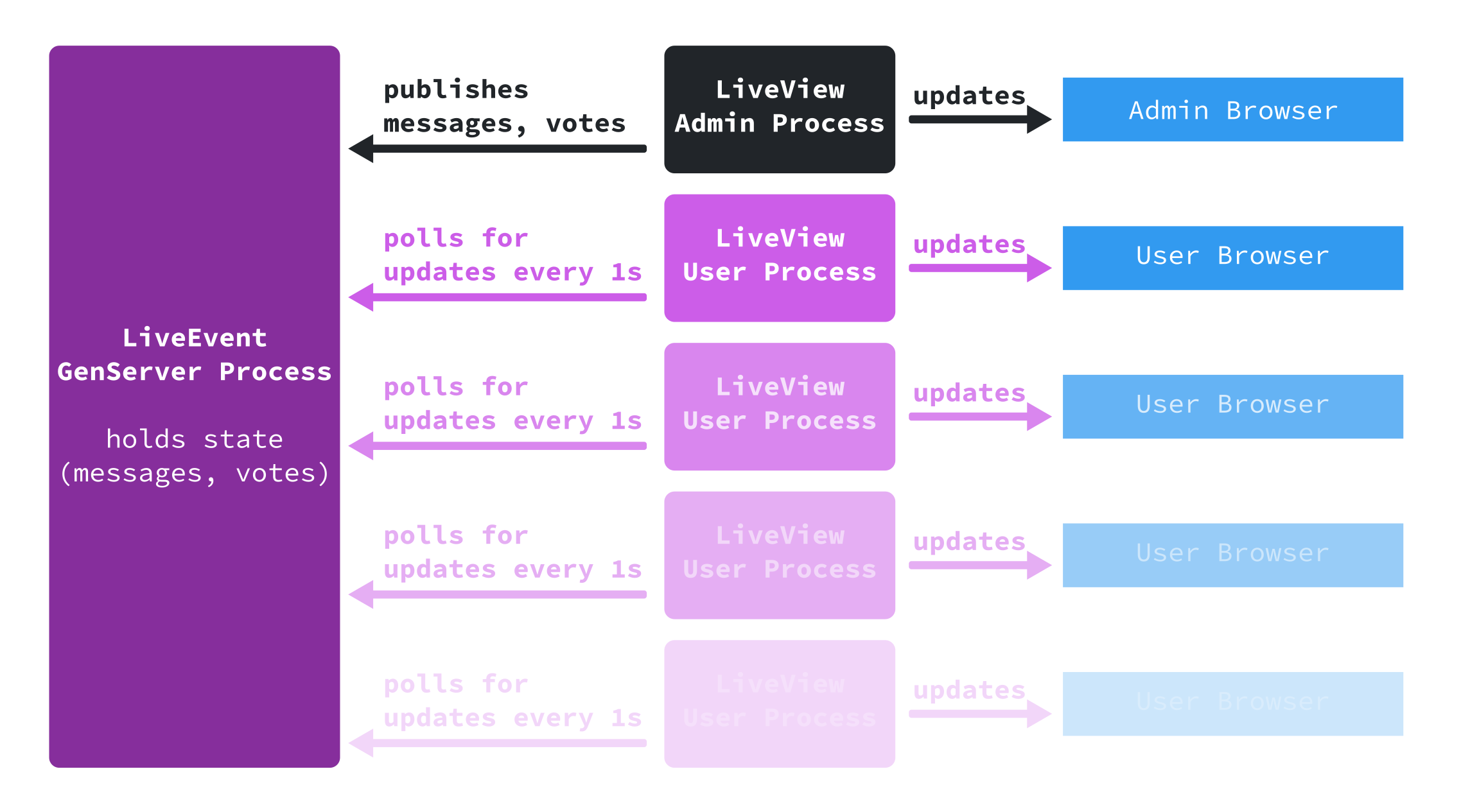
And so, after just two or three weeks of hacking, Volt’s online assembly tool, Tusker, was born. It allowed the convention chairs to share messages and votes with participants, and participants to take part in votes. The architecture of the tool was rather straightforward:
- All information about the state of the event is held in a long-running
GenServerprocess. - Admins can publish votes and messages to the
GenServerprocess. - Participants poll the
GenServerfor updates every second.
The event in Sofia ended up being a great success for what was likely one of the first LiveView production deployments in the world!
As the COVID-19 pandemic hit, other political parties all across the globe were forced to completely rethink their party conventions. Many parties had no previous experience with online assemblies and were left struggling to improvise new solutions. But Volt had Tusker, and local chapters all over Europe had already started using it for their own assemblies.
Everything was great - except for one problem: The party kept growing, and thus the number of participants in these events kept growing, too.
Disaster Strikes
With growing numbers of participants, it became necessary to optimize the application architecture.
The frequent polling intervals of the first iteration ended up maxing out all eight
CPU cores of a t3a.2xlarge AWS EC2 instance.
This was not yet a major problem because the Erlang Virtual Machine with its own
scheduler ensures that applications still run smoothly under these conditions.
But it was clearly not future-proof anymore.
So I decided to switch from constant polling to a Pub/Sub model. This is also quite easy to do with Elixir and Phoenix: Phoenix comes with its own easy-to-use PubSub module.
Instead of querying the event state at regular intervals, participants were now
subscribed to the live_event/:id and live_event/:id/:participant_id topics
on which they’d receive messages about the event as a whole and their own status
in it. In addition, admin users would be subscribed to a live_event/:id/admin topic on
which they’d receive additional information such as updates to the list of
participants.
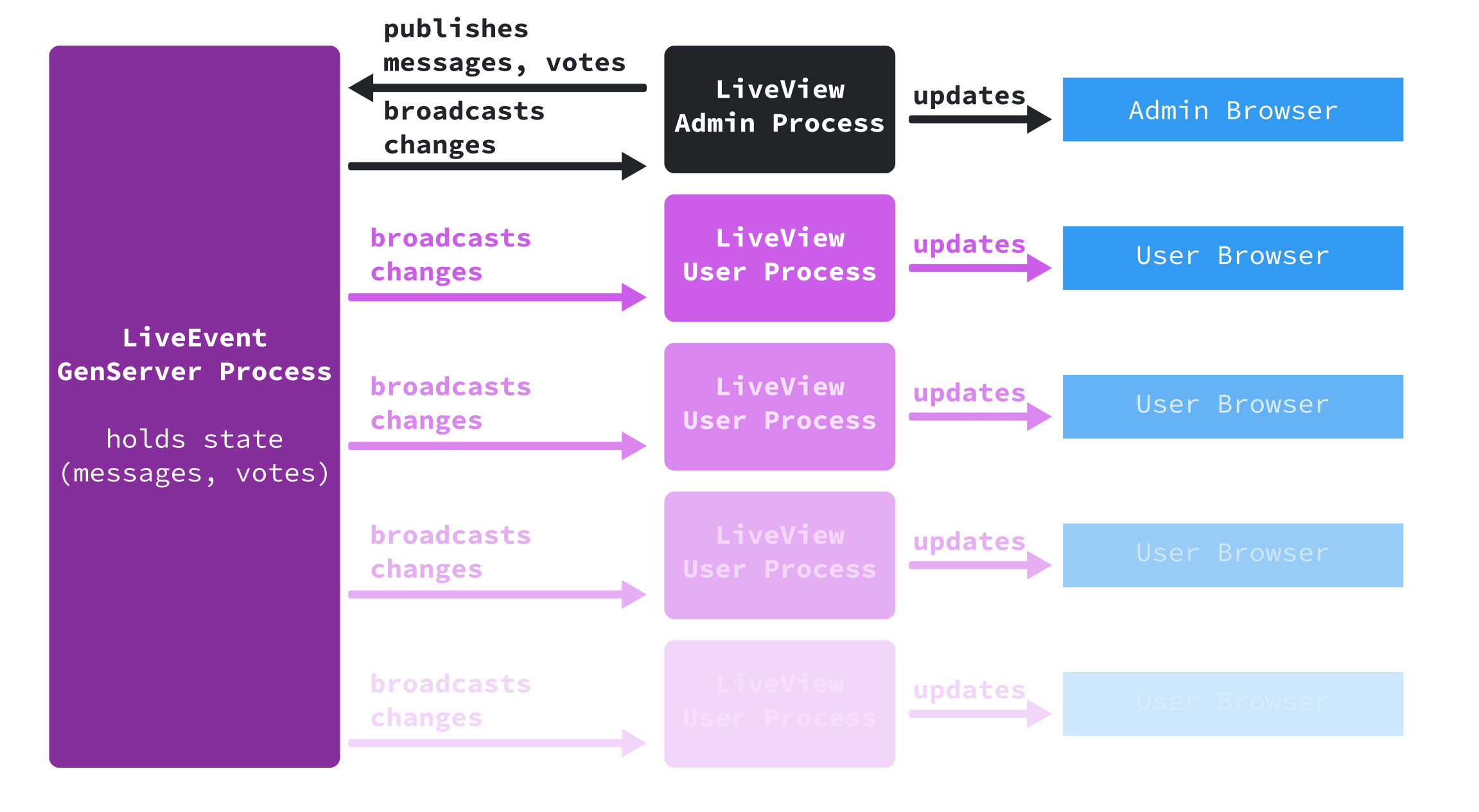
The updated application architecture with Phoenix.PubSub
The code for this in the LiveView controller looks something like this:
def mount(_params, %{id: id}, socket) do
if socket.connected? do
Phoenix.PubSub.subscribe(MyPubSub, "live_event/#{id}")
end
# ...
{:ok, socket}
end
def handle_info({:votes_updated, votes}, socket) do
{:noreply, assign(:votes, votes)
end
My local tests went well, everything was blazingly fast. And CPU use seemed to be greatly reduced. Success! Next, I deployed the updated platform for organizing a couple of small-scale local events for Volt in the Netherlands. That, too, went without a hitch.
It was like watching a trainwreck … until the inevitable out-of-memory crash.
So all seemed well and I was confident to use the new version for a much bigger event: A three-day convention packed with votes and almost 3,000 eligible members in Germany. It was going to go smoothly with the server happily humming along at greatly reduced CPU usage levels. Or so I thought.
The national convention of Volt in Germany was set to begin on Friday, May 28th, at 16:00 CEST. I eagerly watched the admin panel as hundreds of participants were logging into the platform.
But after just two minutes: 502 - Bad Gateway: The application had crashed.
Panicked, I checked the logs - and could find no obvious reason for a crash.
So I restarted the server, this time watching resource usage on htop. It was like
watching a trainwreck: As soon as the server was up again, RAM usage immediately
started climbing, and climbing … until the inevitable out-of-memory crash.
A third attempt also brought, unsurprisingly, no improvement.
Luckily, I was able to roll back to an older version, new invitation links were sent out, and with a mere one-hour delay, the three-day convention could eventually begin.
Investigation Time
Now it was time to investigate. What had gone wrong?
I fired up the Erlang Observer and took a look at the Crashdump Viewer.
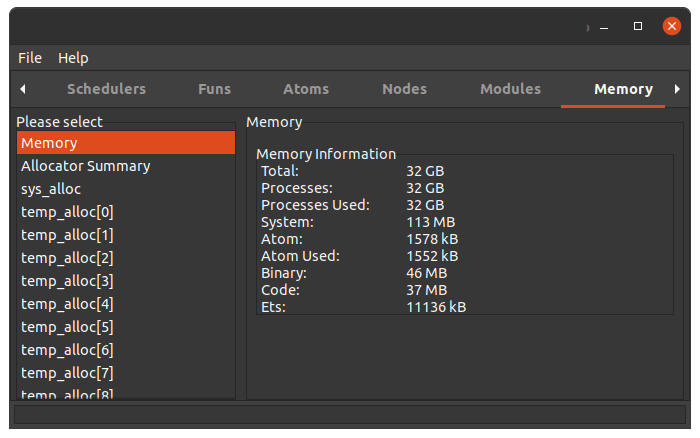
The problem: Processes.
It didn’t take me too long to figure out that moving from polling to Pub/Sub is what had caused the excessive memory consumption.
Whenever a user logged into the platform, the GenServer would broadcast a
complete list of updated participants to all admin users:
PubSub.broadcast(
MyPubSub,
"live_event/#{id}/admin",
{:participants_updated, participants}
)
The LiveView controller process would then receive these messages, set the
@participants assign and render an updated view:
def handle_info({:participants_updated, participants}, socket) do
{ :noreply,
assign(socket, :participants, participants) }
end
My theory was this: With dozens of these updates happening per second as participants were joining the convention, messages were piling up in the inbox of the LiveView admin controller processes faster than they could be handled. With several admin users online, this would quickly lead to excessive memory consumption, filling up all 32 GB of my instance, eventually causing an out-of-memory crash.
To test this theory, I set up an event on my dev machine, opened an admin panel, and started broadcasting 5,000 updates of the participants list. My laptop crashed, the theory had been confirmed!
Fixing the issue
Now it was time to fix the issue.
My first attempt at solving the issue was to try and handle incoming messages
faster at the LiveView controller process level. In order to do so, I tried no longer
directly setting the @participants assign each time the
:participants_updated message hit.
Instead I tried setting a different assign that wasn’t used in the HTML template
and thus causing no delay for re-rendering. I then wanted the LiveView process
to occasionally check if this other assign had been modified and, if so, also
update @participants.
This appeared to work fine. I broadcast 5,000 updates and my laptop didn’t crash. However, when I then tried to use the admin panel in my browser, I noticed that the tab had frozen. As it turns out: Even if an assign is not used in the HTML template, LiveView will still send an (empty) update to the browser. With thousands of updates coming in at the same time, neither Firefox nor Chromium stood a chance.
And besides, this solution still came with the inherent risk of the LiveView controller process’s inbox filling up.
So ultimately, I settled on another solution: Throttling the broadcast frequency
at the GenServer level. Instead of broadcasting the participant list as soon
as a change occurred, I implemented a mechanism to do so at most once every
second.
This can be achieved via a function that gets called in the GenServer process at a given interval:
@process_participants_interval 1000
@impl true
def init(state) do
schedule_process_participants()
# ...
{:ok, state}
end
@impl true
defp schedule_process_participants() do
Process.send_after(
self(),
:process_participants,
@process_participants_interval
)
end
@impl true
def handle_info(:process_participants, state) do
schedule_process_participants()
{:noreply, process_participants(state)}
end
defp process_participants(state = %{participants_stale: true}) do
Phoenix.PubSub.broadcast(
MyPubSub,
"live_event/#{state.id}/admin",
:participants_updated
)
%{state | participants_stale: false}
end
defp process_participants(state), do: state
And since the participants list is no longer included in each broadcast, the LiveView controller process now fetches it when an update occurs:
def handle_info(:participants_updated, socket) do
{:noreply, fetch_participants(socket)}
end
Learnings and Best Practices
The learnings from this somewhat disastrous experience can be summarized in three points:
- Avoid large payloads in
Phoenix.PubSubif possible - Throttle PubSub events at the sender level to avoid clogged process inboxes
- Using
assign/3in LiveView always causes an update via Websocket, even if no changes were made
Will I keep using LiveView for applications such as this one? Absolutely! Even though this is an example how things can go wrong if you’re not careful, LiveView is an amazing technology and we wouldn’t have been able to include thousands of members in political decision-making processes without it.
If you have any questions or if you’re curious how Phoenix and LiveView could benefit your organization, let me know!